Aggregate
The Aggregator from the EIP patterns allows you to combine a number of messages into a single message.
How do we combine the results of individual, but related, messages so that they can be processed as a whole?
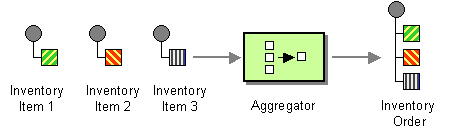
Use a stateful filter, an Aggregator, to collect and store individual messages until a complete set of related messages has been received. Then, the Aggregator publishes a single message distilled from the individual messages.
The aggregator is one of the most complex EIP and has many features and configurations.
The logic for combing messages together is correlated in buckets based on a correlation key. Messages with the same correlation key are aggregated together, using an AggregationStrategy.
Aggregate options
The Aggregate eip supports 7 options, which are listed below.
| Name | Description | Default | Type |
|---|---|---|---|
description | Sets the description of this node. | String | |
disabled | Whether to disable this EIP from the route during build time. Once an EIP has been disabled then it cannot be enabled later at runtime. | false | Boolean |
correlationExpression | Required The expression used to calculate the correlation key to use for aggregation. The Exchange which has the same correlation key is aggregated together. If the correlation key could not be evaluated an Exception is thrown. You can disable this by using the ignoreBadCorrelationKeys option. | ExpressionSubElementDefinition | |
completionPredicate | A Predicate to indicate when an aggregated exchange is complete. If this is not specified and the AggregationStrategy object implements Predicate, the aggregationStrategy object will be used as the completionPredicate. | ExpressionSubElementDefinition | |
completionTimeoutExpression | Time in millis that an aggregated exchange should be inactive before its complete (timeout). This option can be set as either a fixed value or using an Expression which allows you to evaluate a timeout dynamically - will use Long as result. If both are set Camel will fallback to use the fixed value if the Expression result was null or 0. You cannot use this option together with completionInterval, only one of the two can be used. By default the timeout checker runs every second, you can use the completionTimeoutCheckerInterval option to configure how frequently to run the checker. The timeout is an approximation and there is no guarantee that the a timeout is triggered exactly after the timeout value. It is not recommended to use very low timeout values or checker intervals. | ExpressionSubElementDefinition | |
completionSizeExpression | Number of messages aggregated before the aggregation is complete. This option can be set as either a fixed value or using an Expression which allows you to evaluate a size dynamically - will use Integer as result. If both are set Camel will fallback to use the fixed value if the Expression result was null or 0. | ExpressionSubElementDefinition | |
optimisticLockRetryPolicy | Allows to configure retry settings when using optimistic locking. | OptimisticLockRetryPolicyDefinition | |
parallelProcessing | When aggregated are completed they are being send out of the aggregator. This option indicates whether or not Camel should use a thread pool with multiple threads for concurrency. If no custom thread pool has been specified then Camel creates a default pool with 10 concurrent threads. | false | Boolean |
optimisticLocking | Turns on using optimistic locking, which requires the aggregationRepository being used, is supporting this by implementing org.apache.camel.spi.OptimisticLockingAggregationRepository . | false | Boolean |
executorService | If using parallelProcessing you can specify a custom thread pool to be used. In fact also if you are not using parallelProcessing this custom thread pool is used to send out aggregated exchanges as well. | ExecutorService | |
timeoutCheckerExecutorService | If using either of the completionTimeout, completionTimeoutExpression, or completionInterval options a background thread is created to check for the completion for every aggregator. Set this option to provide a custom thread pool to be used rather than creating a new thread for every aggregator. | ScheduledExecutorService | |
aggregateController | To use a org.apache.camel.processor.aggregate.AggregateController to allow external sources to control this aggregator. | AggregateController | |
aggregationRepository | The AggregationRepository to use. Sets the custom aggregate repository to use. Will by default use org.apache.camel.processor.aggregate.MemoryAggregationRepository. | AggregationRepository | |
aggregationStrategy | The AggregationStrategy to use. For example to lookup a bean with the name foo, the value is simply just #bean:foo. Configuring an AggregationStrategy is required, and is used to merge the incoming Exchange with the existing already merged exchanges. At first call the oldExchange parameter is null. On subsequent invocations the oldExchange contains the merged exchanges and newExchange is of course the new incoming Exchange. | AggregationStrategy | |
aggregationStrategyMethodName | This option can be used to explicit declare the method name to use, when using beans as the AggregationStrategy. | String | |
aggregationStrategyMethodAllowNull | If this option is false then the aggregate method is not used for the very first aggregation. If this option is true then null values is used as the oldExchange (at the very first aggregation), when using beans as the AggregationStrategy. | false | Boolean |
completionSize | Number of messages aggregated before the aggregation is complete. This option can be set as either a fixed value or using an Expression which allows you to evaluate a size dynamically - will use Integer as result. If both are set Camel will fallback to use the fixed value if the Expression result was null or 0. | Integer | |
completionInterval | A repeating period in millis by which the aggregator will complete all current aggregated exchanges. Camel has a background task which is triggered every period. You cannot use this option together with completionTimeout, only one of them can be used. | String | |
completionTimeout | Time in millis that an aggregated exchange should be inactive before its complete (timeout). This option can be set as either a fixed value or using an Expression which allows you to evaluate a timeout dynamically - will use Long as result. If both are set Camel will fallback to use the fixed value if the Expression result was null or 0. You cannot use this option together with completionInterval, only one of the two can be used. By default the timeout checker runs every second, you can use the completionTimeoutCheckerInterval option to configure how frequently to run the checker. The timeout is an approximation and there is no guarantee that the a timeout is triggered exactly after the timeout value. It is not recommended to use very low timeout values or checker intervals. | String | |
completionTimeoutCheckerInterval | Interval in millis that is used by the background task that checks for timeouts ( org.apache.camel.TimeoutMap ). By default the timeout checker runs every second. The timeout is an approximation and there is no guarantee that the a timeout is triggered exactly after the timeout value. It is not recommended to use very low timeout values or checker intervals. | 1000 | String |
completionFromBatchConsumer | Enables the batch completion mode where we aggregate from a org.apache.camel.BatchConsumer and aggregate the total number of exchanges the org.apache.camel.BatchConsumer has reported as total by checking the exchange property org.apache.camel.Exchange#BATCH_COMPLETE when its complete. This option cannot be used together with discardOnAggregationFailure. | false | Boolean |
completionOnNewCorrelationGroup | Enables completion on all previous groups when a new incoming correlation group. This can for example be used to complete groups with same correlation keys when they are in consecutive order. Notice when this is enabled then only 1 correlation group can be in progress as when a new correlation group starts, then the previous groups is forced completed. | false | Boolean |
eagerCheckCompletion | Use eager completion checking which means that the completionPredicate will use the incoming Exchange. As opposed to without eager completion checking the completionPredicate will use the aggregated Exchange. | false | Boolean |
ignoreInvalidCorrelationKeys | If a correlation key cannot be successfully evaluated it will be ignored by logging a DEBUG and then just ignore the incoming Exchange. | false | Boolean |
closeCorrelationKeyOnCompletion | Closes a correlation key when its complete. Any late received exchanges which has a correlation key that has been closed, it will be defined and a ClosedCorrelationKeyException is thrown. | Integer | |
discardOnCompletionTimeout | Discards the aggregated message on completion timeout. This means on timeout the aggregated message is dropped and not sent out of the aggregator. | false | Boolean |
discardOnAggregationFailure | Discards the aggregated message when aggregation failed (an exception was thrown from AggregationStrategy . This means the partly aggregated message is dropped and not sent out of the aggregator. This option cannot be used together with completionFromBatchConsumer. | false | Boolean |
forceCompletionOnStop | Indicates to complete all current aggregated exchanges when the context is stopped. | false | Boolean |
completeAllOnStop | Indicates to wait to complete all current and partial (pending) aggregated exchanges when the context is stopped. This also means that we will wait for all pending exchanges which are stored in the aggregation repository to complete so the repository is empty before we can stop. You may want to enable this when using the memory based aggregation repository that is memory based only, and do not store data on disk. When this option is enabled, then the aggregator is waiting to complete all those exchanges before its stopped, when stopping CamelContext or the route using it. | false | Boolean |
outputs | Required | List |
Exchange properties
The Aggregate eip supports 7 exchange properties, which are listed below.
The exchange properties are set on the Exchange by the EIP, unless otherwise specified in the description. This means those properties are available after this EIP has completed processing the Exchange.
| Name | Description | Default | Type |
|---|---|---|---|
CamelAggregatedSize | Number of exchanges that was grouped together. | int | |
CamelAggregatedTimeout | The time in millis this group will timeout. | long | |
CamelAggregatedCompletedBy | Enum that tell how this group was completed. | String | |
CamelAggregatedCorrelationKey | The correlation key for this aggregation group. | String | |
CamelAggregationCompleteCurrentGroup | Input property. Set to true to force completing the current group. This allows to overrule any existing completion predicates, sizes, timeouts etc, and complete the group. | boolean | |
CamelAggregationCompleteAllGroups | Input property. Set to true to force completing all the groups (excluding this message). This allows to overrule any existing completion predicates, sizes, timeouts etc, and complete the group. This message is considered a signal message only, the message headers/contents will not be processed otherwise. Instead use CamelAggregationCompleteAllGroupsInclusive if this message should be included in the aggregator. | boolean | |
CamelAggregationCompleteAllGroupsInclusive | Input property. Set to true to force completing all the groups (including this message). This allows to overrule any existing completion predicates, sizes, timeouts etc, and complete the group. | boolean |
Worker pools
The aggregate EIP will always use a worker pool used to process all the outgoing messages from the aggregator. The worker pool is determined accordingly:
-
If a custom
ExecutorServicehas been configured, then this is used as worker pool. -
If
parallelProcessing=truethen a default worker pool (is 10 worker threads by default) is created. However, the thread pool size and other configurations can be configured using thread pool profiles. -
Otherwise, a single threaded worker pool is created.
-
To achieve synchronous aggregation, use an instance of
SynchronousExecutorServicefor theexecutorServiceoption. The aggregated output will execute in the same thread that called the aggregator.
Aggregating
The AggregationStrategy is used for aggregating the old, and the new exchanges together into a single exchange; that becomes the next old, when the next message is aggregated, and so forth.
Possible implementations include performing some kind of combining or delta processing. For instance, adding line items together into an invoice or just using the newest exchange and removing old exchanges such as for state tracking or market data prices, where old values are of little use.
Notice the aggregation strategy is a mandatory option and must be provided to the aggregator.
| In the aggregate method, do not create a new exchange instance to return, instead return either the old or new exchange from the input parameters; favor returning the old exchange whenever possible. |
Here are a few example AggregationStrategy implementations that should help you create your own custom strategy.
//simply combines Exchange String body values using '+' as a delimiter
class StringAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String oldBody = oldExchange.getIn().getBody(String.class);
String newBody = newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(oldBody + "+" + newBody);
return oldExchange;
}
}
//simply combines Exchange body values into an ArrayList<Object>
class ArrayListAggregationStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
Object newBody = newExchange.getIn().getBody();
ArrayList<Object> list = null;
if (oldExchange == null) {
list = new ArrayList<Object>();
list.add(newBody);
newExchange.getIn().setBody(list);
return newExchange;
} else {
list = oldExchange.getIn().getBody(ArrayList.class);
list.add(newBody);
return oldExchange;
}
}
} The org.apache.camel.builder.AggregationStrategies is a builder that can be used for creating commonly used aggregation strategies without having to create a class. |
Aggregate by grouping exchanges
In the route below we group all the exchanges together using GroupedExchangeAggregationStrategy:
from("direct:start")
// aggregates all using the same expression and group the
// exchanges, so we get one single exchange containing all
// the others
.aggregate(new GroupedExchangeAggregationStrategy()).constant(true)
// wait for 0.5 seconds to aggregate
.completionTimeout(500L).to("mock:result");As a result we have one outgoing Exchange being routed to the "mock:result" endpoint. The exchange is a holder containing all the incoming Exchanges.
The output of the aggregator will then contain the exchanges grouped together in a list as shown below:
List<Exchange> grouped = exchange.getMessage().getBody(List.class);Aggregating into a List
If you want to aggregate some value from the messages <V> into a List<V> then you can use the org.apache.camel.processor.aggregate.AbstractListAggregationStrategy abstract class.
The completed Exchange sent out of the aggregator will contain the List<V> in the message body.
For example, to aggregate a List<Integer> you can extend this class as shown below, and implement the getValue method:
public class MyListOfNumbersStrategy extends AbstractListAggregationStrategy<Integer> {
@Override
public Integer getValue(Exchange exchange) {
// the message body contains a number, so return that as-is
return exchange.getIn().getBody(Integer.class);
}
}The org.apache.camel.builder.AggregationStrategies is a builder that can be used for creating commonly used aggregation strategies without having to create a class.
The previous example can also be built using the builder as shown:
AggregationStrategy agg = AggregationStrategies.flexible(Integer.class)
.accumulateInCollection(ArrayList.class)
.pick(body());Aggregating on timeout
If your aggregation strategy implements TimeoutAwareAggregationStrategy, then Camel will invoke the timeout method when the timeout occurs. Notice that the values for index and total parameters will be -1, and the timeout parameter will be provided only if configured as a fixed value. You must not throw any exceptions from the timeout method.
Aggregate with persistent repository
The aggregator provides a pluggable repository which you can implement your own org.apache.camel.spi.AggregationRepository.
If you need a persistent repository, then Camel provides numerous implementations, such as from the Caffeine, CassandraQL, EHCache, Infinispan, JCache, LevelDB, Redis, or SQL components.
Completion
When aggregation Exchanges at some point, you need to indicate that the aggregated exchanges are complete, so they can be sent out of the aggregator. Camel allows you to indicate completion in various ways as follows:
-
completionTimeout: Is an inactivity timeout in that is triggered if no new exchanges have been aggregated for that particular correlation key within the period.
-
completionInterval: Once every X period all the current aggregated exchanges are completed.
-
completionSize: Is a number indicating that after X aggregated exchanges its complete.
-
completionPredicate: Runs a Predicate when a new exchange is aggregated to determine if we are complete or not. The configured aggregationStrategy can implement the Predicate interface and will be used as the completionPredicate if no completionPredicate is configured. The configured aggregationStrategy can override the
preCompletemethod and will be used as the completionPredicate in pre-complete check mode. See further below for more details. -
completionFromBatchConsumer: Special option for Batch Consumer, which allows you to complete when all the messages from the batch have been aggregated.
-
forceCompletionOnStop: Indicates to complete all current aggregated exchanges when the context is stopped
-
AggregateController: which allows to use an external source (
AggregateControllerimplementation) to complete groups or all groups. This can be done using Java or JMX API.
All the different completions are per correlation key. You can combine them in any way you like. It’s basically the first that triggers that wins. So you can use a completion size together with a completion timeout. Only completionTimeout and completionInterval cannot be used at the same time.
Completion is mandatory and must be configured on the aggregation.
Pre-completion mode
There can be use-cases where you want the incoming Exchange to determine if the correlation group should pre-complete, and then the incoming Exchange is starting a new group from scratch. The pre-completion mode must be enabled by the AggregationStrategy by overriding the canPreComplete method to return a true value.
When pre-completion is enabled then the preComplete method is invoked:
/**
* Determines if the aggregation should complete the current group, and start a new group, or the aggregation
* should continue using the current group.
*
* @param oldExchange the oldest exchange (is <tt>null</tt> on first aggregation as we only have the new exchange)
* @param newExchange the newest exchange (can be <tt>null</tt> if there was no data possible to acquire)
* @return <tt>true</tt> to complete current group and start a new group, or <tt>false</tt> to keep using current
*/
boolean preComplete(Exchange oldExchange, Exchange newExchange);If the preComplete method returns true, then the existing correlation group is completed (without aggregating the incoming exchange (newExchange). Then the newExchange is used to start the correlation group from scratch, so the group would contain only that new incoming exchange. This is known as pre-completion mode.
The newExchange contains the following exchange properties, which can be used to determine whether to pre complete.
| Property | Type | Description |
|---|---|---|
|
| The total number of messages aggregated. |
|
| The correlation identifier as a |
When the aggregation is in pre-completion mode, then only the following completions are in use:
-
completionTimeout or completionInterval can also be used as fallback completions
-
any other completions are not used (such as by size, from batch consumer, etc.)
-
eagerCheckCompletion is implied as
true, but the option has no effect
CompletionAwareAggregationStrategy
If your aggregation strategy implements CompletionAwareAggregationStrategy, then Camel will invoke the onComplete method when the aggregated Exchange is completed. This allows you to do any last minute custom logic such as to clean up some resources, or additional work on the exchange as it’s now completed. You must not throw any exceptions from the onCompletion method.
Completing the current group decided from the AggregationStrategy
The AggregationStrategy supports checking for the exchange property (Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP) on the returned Exchange that contains a boolean to indicate if the current group should be completed. This allows to overrule any existing completion predicates / sizes / timeouts etc., and complete the group.
For example, the following logic will complete the group if the message body size is larger than 5. This is done by setting the exchange property Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP to true.
public final class MyCompletionStrategy implements AggregationStrategy {
@Override
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
return newExchange;
}
String body = oldExchange.getIn().getBody(String.class) + "+"
+ newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(body);
if (body.length() >= 5) {
oldExchange.setProperty(Exchange.AGGREGATION_COMPLETE_CURRENT_GROUP, true);
}
return oldExchange;
}
}Completing all previous group decided from the AggregationStrategy
The AggregationStrategy checks an exchange property, from the returned exchange, indicating if all previous groups should be completed.
This allows to overrule any existing completion predicates / sizes / timeouts etc., and complete all the existing previous group.
The following logic will complete all the previous groups, and start a new aggregation group.
This is done by setting the property Exchange.AGGREGATION_COMPLETE_ALL_GROUPS to true on the returned exchange.
public final class MyCompletionStrategy implements AggregationStrategy {
@Override
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
if (oldExchange == null) {
// we start a new correlation group, so complete all previous groups
newExchange.setProperty(Exchange.AGGREGATION_COMPLETE_ALL_GROUPS, true);
return newExchange;
}
String body1 = oldExchange.getIn().getBody(String.class);
String body2 = newExchange.getIn().getBody(String.class);
oldExchange.getIn().setBody(body1 + body2);
return oldExchange;
}
}Manually force the completion of all aggregated Exchanges immediately
You can manually trigger completion of all current aggregated exchanges by sending an exchange containing the exchange property Exchange.AGGREGATION_COMPLETE_ALL_GROUPS set to true. The message is considered a signal message only, the message headers/contents will not be processed otherwise.
You can alternatively set the exchange property Exchange.AGGREGATION_COMPLETE_ALL_GROUPS_INCLUSIVE to true to trigger completion of all groups after processing the current message.
Using a controller to force the aggregator to complete
The org.apache.camel.processor.aggregate.AggregateController allows you to control the aggregate at runtime using Java or JMX API. This can be used to force completing groups of exchanges, or query its current runtime statistics.
The aggregator provides a default implementation if no custom one has been configured, which can be accessed using getAggregateController() method. Though it may be easier to configure a controller in the route using aggregateController as shown below:
private AggregateController controller = new DefaultAggregateController();
from("direct:start")
.aggregate(header("id"), new MyAggregationStrategy())
.completionSize(10).id("myAggregator")
.aggregateController(controller)
.to("mock:aggregated");Then there is API on AggregateController to force completion. For example, to complete a group with key foo:
int groups = controller.forceCompletionOfGroup("foo");The returned value is the number of groups completed. A value of 1 is returned if the foo group existed, otherwise 0 is returned.
There is also a method to complete all groups:
int groups = controller.forceCompletionOfAllGroups();The controller can also be used in XML DSL using the aggregateController to refer to a bean with the controller implementation, which is looked up in the registry.
When using Spring XML, you can create the bean with <bean> as shown:
<bean id="myController" class="org.apache.camel.processor.aggregate.DefaultAggregateController"/>
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate aggregationStrategy="myAppender" completionSize="10"
aggregateController="myController">
<correlationExpression>
<header>id</header>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>There is also JMX API on the aggregator which is available under the processors node in the Camel JMX tree.
Aggregating with Beans
To use the AggregationStrategy you had to implement the org.apache.camel.AggregationStrategy interface, which means your logic would be tied to the Camel API. You can use a bean for the logic and let Camel adapt to your bean. To use a bean, then a convention must be followed:
-
there must be a public method to use
-
the method must not be void
-
the method can be static or non-static
-
the method must have two or more parameters
-
the parameters are paired, so the first half is applied to the
oldExchange, and the reminder half is for thenewExchange. Therefore, there must be an equal number of parameters, e.g., 2, 4, 6, etc.
The paired methods are expected to be ordered as follows:
-
the first parameter is the message body
-
optional, the second parameter is a
Mapof the headers -
optional, the third parameter is a
Mapof the exchange properties
This convention is best explained with some examples.
In the method below, we have only two parameters, so the first parameter is the body of the oldExchange, and the second is paired to the body of the newExchange:
public String append(String existing, String next) {
return existing + next;
}In the method below, we have only four parameters, so the first parameter is the body of the oldExchange, and the second is the Map of the oldExchange headers, and the third is paired to the body of the newExchange, and the fourth parameter is the Map of the newExchange headers:
public String append(String existing, Map existingHeaders, String next, Map nextHeaders) {
return existing + next;
}And finally, if we have six parameters, that includes the exchange properties:
public String append(String existing, Map existingHeaders, Map existingProperties,
String next, Map nextHeaders, Map nextProperties) {
return existing + next;
}To use this with the aggregate EIP, we can use a bean with the aggregate logic as follows:
public class MyBodyAppender {
public String append(String existing, String next) {
return next + existing;
}
}And then in the Camel route we create an instance of our bean, and then refer to the bean in the route using bean method from org.apache.camel.builder.AggregationStrategies as shown:
private MyBodyAppender appender = new MyBodyAppender();
public void configure() throws Exception {
from("direct:start")
.aggregate(constant(true), AggregationStrategies.bean(appender, "append"))
.completionSize(3)
.to("mock:result");
}We can also provide the bean class type directly:
public void configure() throws Exception {
from("direct:start")
.aggregate(constant(true), AggregationStrategies.bean(MyBodyAppender.class, "append"))
.completionSize(3)
.to("mock:result");
}And if the bean has only one method, we do not need to specify the name of the method:
public void configure() throws Exception {
from("direct:start")
.aggregate(constant(true), AggregationStrategies.bean(MyBodyAppender.class))
.completionSize(3)
.to("mock:result");
}And the append method could be static:
public class MyBodyAppender {
public static String append(String existing, String next) {
return next + existing;
}
}If you are using XML DSL, then we need to declare a <bean> with the bean:
<bean id="myAppender" class="com.foo.MyBodyAppender"/>And in the Camel route we use aggregationStrategy to refer to the bean by its id, and the strategyMethodName can be used to define the method name to call:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate aggregationStrategy="myAppender" aggregationStrategyMethodName="append" completionSize="3">
<correlationExpression>
<constant>true</constant>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>When using XML DSL, you can also specify the bean class directly in aggregationStrategy using the #class: syntax as shown:
<route>
<from uri="direct:start"/>
<aggregate aggregationStrategy="#class:com.foo.MyBodyAppender" aggregationStrategyMethodName="append" completionSize="3">
<correlationExpression>
<constant>true</constant>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>You can use this in XML DSL when you are not using the classic Spring XML files ( where you use XML only for Camel routes).
Aggregating when no data
When using bean as AggregationStrategy, then the method is only invoked when there is data to be aggregated, meaning that the message body is not null. In cases where you want to have the method invoked, even when there are no data (message body is null), then set the strategyMethodAllowNull to true.
When using beans, this can be configured a bit easier using the beanAllowNull method from AggregationStrategies as shown:
public void configure() throws Exception {
from("direct:start")
.pollEnrich("seda:foo", 1000, AggregationStrategies.beanAllowNull(appender, "append"))
.to("mock:result");
}Then the append method in the bean would need to deal with the situation that newExchange can be null:
public class MyBodyAppender {
public String append(String existing, String next) {
if (next == null) {
return "NewWasNull" + existing;
} else {
return existing + next;
}
}
}In the example above we use the Content Enricher EIP using pollEnrich. The newExchange will be null in the situation we could not get any data from the "seda:foo" endpoint, and a timeout was hit after 1 second.
So if we need to do special merge logic, we would need to set setAllowNullNewExchange=true. If we didn’t do this, then on timeout the append method would normally not be invoked, meaning the Content Enricher did not merge/change the message.
In XML DSL you would configure the strategyMethodAllowNull option and set it to true as shown below:
<camelContext xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:start"/>
<aggregate aggregationStrategy="myAppender"
aggregationStrategyMethodName="append"
aggregationStrategyMethodAllowNull="true"
completionSize="3">
<correlationExpression>
<constant>true</constant>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>
</camelContext>Aggregating with different body types
When, for example, using strategyMethodAllowNull as true, then the parameter type of the message bodies does not have to be the same. For example suppose we want to aggregate from a com.foo.User type to a List<String> that contains the name of the user. We could code a bean as follows:
public final class MyUserAppender {
public List addUsers(List names, User user) {
if (names == null) {
names = new ArrayList();
}
names.add(user.getName());
return names;
}
}Notice that the return type is a List which we want to contain the name of the users. The first parameter is the List of names, and the second parameter is the incoming com.foo.User type.